Suicide Risk Dectection On Social Media
IEEE BigData Cup 2024
1. Introduction
The increasing frequency of suicidal thoughts highlights the importance of early detection and intervention. Social media platforms, where users often share personal experiences and seek help, could be utilized to identify individuals at risk. However, the large volume of daily posts makes manual review impractical.
This project explores the use of Large Language Models (LLMs) to automatically detect suicidal content on social media through user posts (i.e., text).
Our method achieved a score of 75.436, the highest overall evaluation based on model performance (6th on private board with an F1 of 0.7312), approach innovation, and report quality at IEEE BigData 2024 Cup: Detection of suicide risk on social media Competition.
You can read our IEEE Big Data 2024 paper for more details: Leveraging Large Language Models for Suicide Detection on Social Media with Limited Labels.
2. Dataset
The dataset used in this study comprises a training set of 500 labeled and 1,500 unlabeled Reddit posts. An example of a Reddit post in the training set is shown as follows. “I want to end it, I want to end it but I don’t know how, when or anything else”.
3. Method
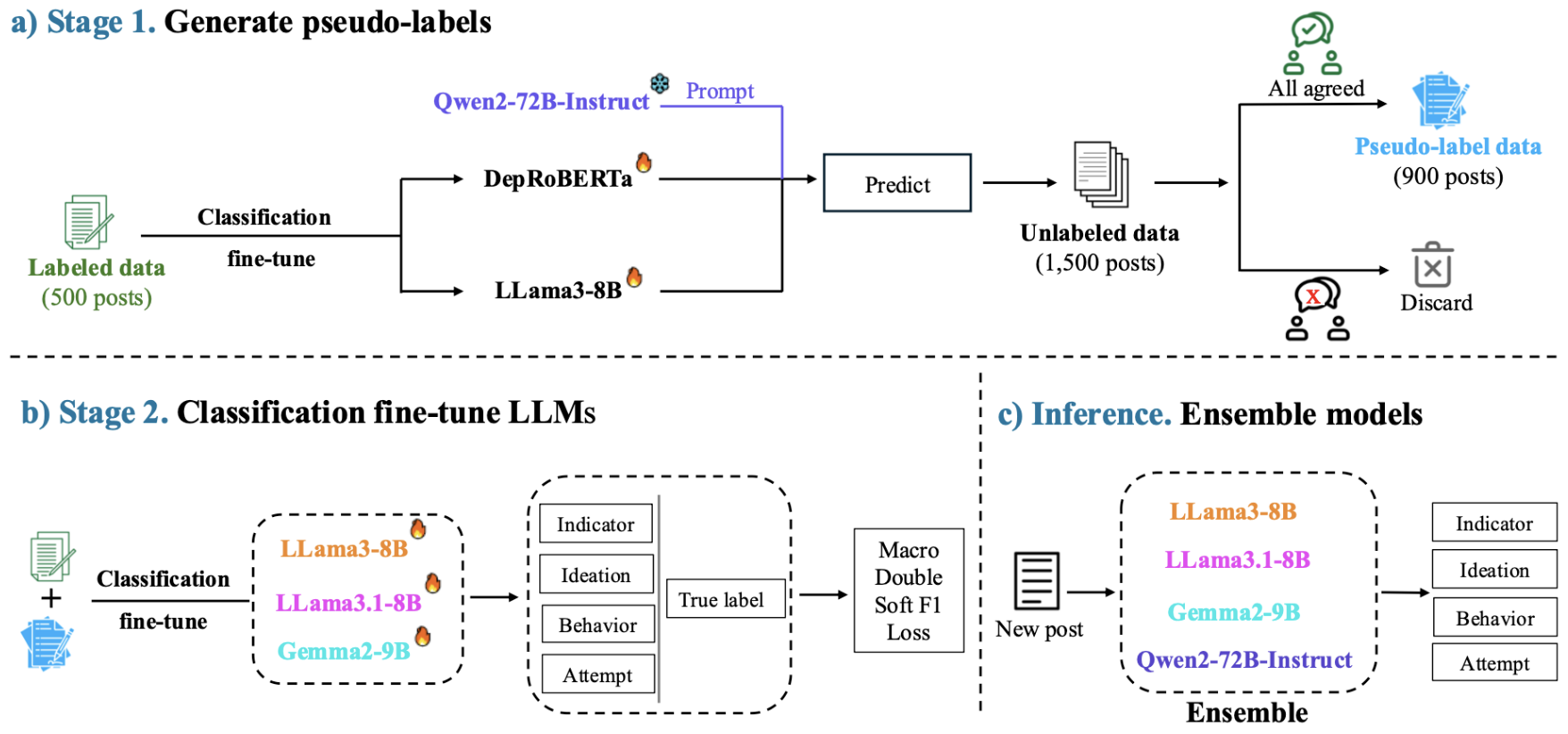
(a) Pseudo-labels generation for unlabeled data. 500 labeled posts are used to fine-tune DepRoBERTa and Llama3-8B for the classification task. Then, these models are combined with Qwen2-72B-Instruct via prompting to annotate 1,500 posts in the unlabeled dataset. We keep only ≈ 900 posts for which all three models predict the same and combine these with the 500 labeled posts to form a new training set.
(b) LLMs fine-tuning. We then fine-tune Llama3-8B, Llama3.1-8B, and Gemma2-9B on the newly formed dataset with Macro Double Soft F1 loss.
(c) Model Ensembling. These fine-tuned models are combined with prompting Qwen2-72B-Instruct to create an ensemble model for classifying new user posts
4. Metrics
Accuracy and weighted F1 scores are recorded for evaluating the model’s performance. We utilize the weighted F1 score as the main metric since it provides abalanced measure of precision and recall, while also addressing class imbalance.
5. Source Code and Checkpoints
- You can find the source code and checkpoints of the project here.